Preamble
During the Inspire 2015 conference in Boston, MA, a theme used for the conference was “Analytic Independence”. With the fourth of July coming on Monday and our Juno space probe diving down towards Jupiter after traveling 1.8 billion miles in 5 years, I thought it would be a good idea to publish this post today because if you work hard enough on something tough, you can overcome the obstacles.
Sometimes my articles can be a bit long. That is OK with me because it has taken me years of work to be able to write those types of articles. Additionally, if you think any particular article is too long for you to read, just imagine how many hours it took me to do the work, explain the method, and write this article!
I think you are getting the better part of the deal, time-wise, at least! I take many hours of work and collapse the knowledge gained during those hours into minutes of reading time.
This might be one of those long articles, but I’m not going to apologize for it. I wish I had been able to read an article like this when I began using Alterxy. So if you have an aversion to learning, skip this article and just try to get a ride in the bus!

Introduction
When faced with solving tough data challenges on your job, you can do a couple of things. First, you can invite the brilliant Ned Harding of Alteryx to meet you in the new Alteryx Bus (Figure 1) to brainstorm and help you solve your problem. That might be hard to do, however, since Ned is in Colorado and the bus is in California.
Second, you can adopt some of the strategies I mention in this article. These strategies have helped me overcome some tough issues I have faced when pushing the limits of combining disparate data sources to produce insights to business operations.

Figure 1 – The new Alteryx Bus. If you don’t know what I’m talking about, click the link in the text.
The Example
I could go into great detail about the project from which this example originates, but that story will have to be written later. I want to focus on a small portion of the project to enable me to explain the strategies I use in Alteryx for overcoming big challenges. The purpose of this article is to discuss strategies and methods, not how I solved this particular problem.
This article is not completely comprehensive and will not teach you all that you need to know about using Alteryx. I don’t have that capability – yet. There are some things in here that are creative and insightful and have been produced by my unique combination of education and work experience. So I offer them to you as a way to advance your abilities in Alteryx when you face tough challenges on the job.
In this example, I had to join data from two systems: a travel booking system and an expense report system. One primary problem in doing this was that the systems were not designed to work together. They are maintained by different companies and were not expected to “talk” to each other.
Luckily, there are a few fields that allow us to make some connections using the databases to be able to quantify how people are transported via air travel (i.e., where they go, when they go, how much it costs, etc). Data connections can be made using employee names, airline ticket numbers, and prices paid.
Of course, with this being the real world, the airline tickets numbers are not stored in the same format in each database. The booking system uses a 10-digit number and the expense reporting system uses a longer number (up to 27 digits) to store the airline ticket numbers. Luckily, for about 90% of the booked tickets, it is possible to find the 10-digit number buried in the 27-digit number. As far as finding ways to match up the other 10% of the tickets, that is an ongoing area of research.
Identifying Trips That Were Booked But Never Taken
Now quickly diving into details, consider the following. You have tens of thousands of people traveling domestically and internationally. These people are going everywhere, all of the time. People make travel plans, but sometimes these plans have to change. These changes introduce a level of data complexity that can be described with the following statements:
- A trip is booked and paid for. The trip gets canceled. A full refund is given to the traveler on the same ticket. One booking record has to be matched to two expense records (original price paid and the refunded amount). This is the easiest case to match. (Step 3a)
- A trip is booked and paid for. The trip gets canceled. A full refund is given on another ticket number. (Step 3b)
- A trip is booked and paid for. The trip gets canceled. A partial refund (you sometimes have to pay a fee to cancel) is given to the traveler on the same ticket number. (Step 3c)
- A trip is booked and gets paid for. The trip gets canceled. A partial refund is given to another ticket number, not related to the first. This is the hardest case to match. (Step 4b)
In all these cases, an original booking has to be related to a doublet of expenses (one for the original ticket and one for the refund). In all cases, the travel start date assigned when the ticket purchased cannot be directly related to when the expense reports are filed because a common date field does not exist. The closest date connection we have is comparing the number of days between the anticipated travel start date and the expense report submission date.
The reason I want to identify these types of “null trips” is that I want to remove them from the data set before I complete my analysis. If I don’t do this work, it looks like two trips were taken when in actuality, no trip was taken.
The Alteryx Methods I Use To Help Me Do This Type of Work
The following list contains a number of techniques that I use to solve problems like these. For each method, I discuss how to use it and why it is important.
Part 1 – Alteryx Fundamentals
If you are going to develop complex workflows, you need to know how use workflow logging and how to find specific tools in your workflow to be able to optimize performance. To turn on logging, you have to enter a directory to store the logging files as shown in Figure 2 (Options/User settings).

Figure 2 – How to turn on workflow logging in Alteryx.
To find tools in a workflow, you simply use the Ctrl-F (find) to load the menu showing the tools used in your workflow. To learn a little more about using Alteryx fundamentals for more complex workflows, you can watch the video below.
Part 2 – Workflow Development Techniques
There are a number of techniques I use to build more complex workflows. Just like I used to do when writing complex computer programs, I focus on one topic at a time.
In this example from 1999 (click to download pdf file), I wrote a program to perform time-based integrations of groundwater flow and contaminant levels to calculate the mass of contaminants removed from pumping wells. This application had some complexity and required me to develop the computational mathematics, perform testing and check the results carefully because hundreds of millions of dollars were at stake in designing and building of several regional groundwater remediation systems.
All the elements I used in that case are beginning to show up in my Alteryx work. If you actually take the time to review that code, you will see clear documentation, an organized code broken down into discrete computational elements (subroutines), and well-designed data structures used to hold the data and store the results.
When doing this type of work, I usually write a workflow (or a subroutine or function) to solve a piece of the problem before moving to the next step. I typically do testing of the workflow or code to ensure that it is correctly doing what I need it to do before moving to the next step.
By breaking jobs down into pieces, it is easier to debug the workflow in the future when the conditions of your data change or when you have to pass the job onto someone else. If you don’t do the work this way, you will find yourself entangled in a web of complexity that is hard to explain and understand.
This actually happened to me on this airline ticket job and the resulting workflow got to be too knarly without completely solving the problem. I had data connections flying everywhere, and the workflow looked like a plate of spaghetti.
The day after that happened, I started over and began applying the principles that I am outlining in this article (which helped me realize that I needed to write this article). So if you find yourself with a big plate of pasta in Alteryx, consider starting over and completing the building blocks of your solution one piece at a time.
The piecewise solution technique allows you to take the time to document what the workflow is doing. It is always tempting to try to fly to the end of the job to get to the answer(s), but patience and discipline are required to write good workflows that can be reused and understood by others that weren’t initially a part of the project. As an aside, if you watch the Alteryx bus video, the Alteryx CEO Dean Stoecker starts the video with commentary that says the same thing!
The use of tool containers and tool annotations help you to logically group each computational step and to document what the workflow is doing. You can format the annotations to put them on top or on the bottom of the tool to be able to make workflows that are self-documenting, as shown in Figures 3 and 4. The title at the top of the tool container can be used to explain what is happening within the container.

Figure 3 – Step 3a of the workflow. This workflow contains a technique for removing records that I think is clever and efficient. I discuss this technique later in the article (see the 5th technique listed below).
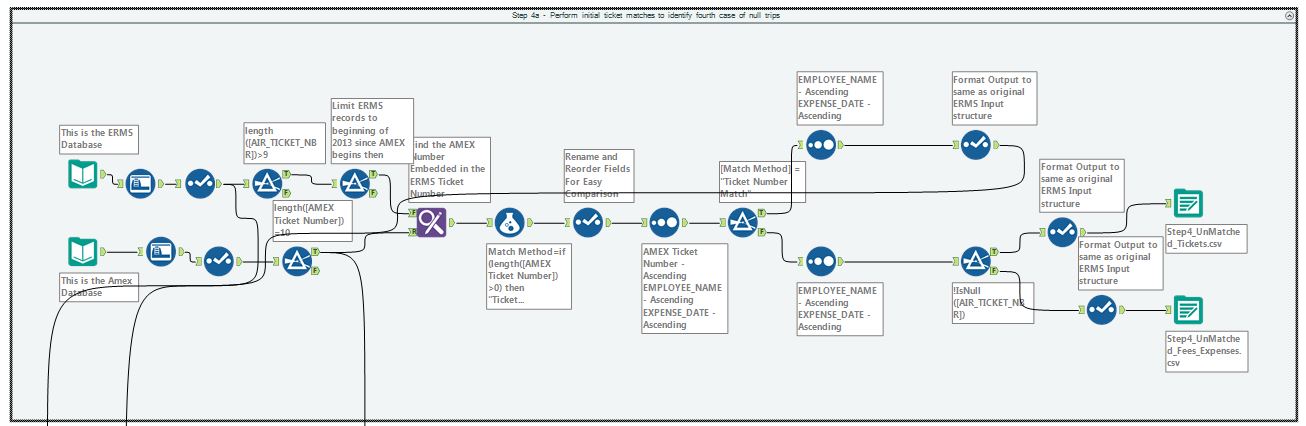
Figure 4 – Step 4a of the workflow.
Finally, once you have assembled the component pieces of the job, it is very easy to stitch them together into a more comprehensive workflow as shown in Figures 5a and 5b.

Figure 5a – Complete workflow (version 1) showing how individual steps are stitched together.

Figure 5b – Complete workflow (version 2) showing how individual steps are stitched together.
Part 3 – Using Tableau to Visualize Workflow Results
I have had a long-term appreciation for the Tableau software company. Although the mission of Tableau is to visualize and tell data stories, I use Tableau in another way just about every day. I use Tableau as a part of the debugging process when I am building complex workflows. I simply could not do the work that I am able to do without this part of the process.
Tableau visualizations allow me to see when I get the algorithms right. When you are dealing with millions of lines of data input and many conditionals and potential data quality issues present in the data, being able to visualize the results of an Alteryx workflow saves huge amounts of time.
Figure 6 is an example of how I used Tableau during the completion of this work. I needed to be sure that the records I removed were indeed what I thought they were. With thousands of “null trips” being removed from the data set, there is no better way to check your work than by developing some quick visuals to perform the quality assurance needed on the workflow. This procedure is not necessarily sexy and won’t win you a viz of the day award, but it is critically important to the success of the work.

Figure 6 – The null trips identified and removed from the four steps described above. I know the results are correct because all of the null trips have roughly equal but opposite prices and refunds.
Part 4 – Specific Tool Usage
I have realized over the past several years that I am developing a method and style to how I develop Alteryx workflows. These things will happen to you the more you practice working with Alteryx.
Although many times the workflows I produce are short and easy to follow, when the complexity rises, the items I outline here can really help you get things done. The list below is not completely comprehensive, but my favorite techniques are included. For more information on writing efficient workflows and using best practices, click here.
Although I am not quite in the Alteryx zone like I described in this Table Data Zone article, I’m getting closer to achieving the complete vision and expertise to do whatever I want to do in Alteryx very efficiently. Here are some of the things I find myself doing in the majority of my workflows.
1 – Using In-Database Tools or Custom Query Building
When pulling data from a networked data source, I use in-database tools or the visual query builder as shown in Figure 7. This allows me to select only the fields that I will need for my analysis. Figure 8 demonstrate the resulting SQL query that Alteryx created to pull about 13 fields from a table containing over 250 fields.
If I had not been selective in what I returned from the database, the workflow would have taken hours to return 7M records * 250 fields instead of the less than 1 hour to return the data I really wanted. The surgical selection of data from big database tables is one of Alteryx’s greatest strengths and that is why they continue to develop more in-database tools. For more information on this technique, you can read this article.
One other key strategy I use with this technique is to initially limit the number of records to a moderate number (1,000 is typical) when I’m building the workflow and testing the logic. Once the logic is correct, I remove the record limitation so that the entire data set is consumed. This technique saves a lot of time.

Figure 7 – The visual query builder for customizing the fields you want to include in your workflow.

Figure 8 – The custom SQL command created by Alteryx to pull the data I specified in Figure 7. You can edit this query to add additional control like I did with the where command at the end of the query.
2 – Using the Record ID Tool
I use record counters for all incoming data files. The record counters allow you to access the complete level of data detail when you send the data to Tableau. The record counters also make row-based operations much easier, such as adding and subtracting rows, much like I did in this example when I had to remove selected records. The Record ID tool is shown in Figure 8.
If your record counts go above the number 4,294,967,295, be sure to set the field type to int64. Also, be sure to change the field name from the default of RecordID to something like File1_RecordID to avoid having duplicate field names.

Figure 8 – Installing the record counter tool.
3 – Removing Duplicate Records
Even when you are certain that your data files do not contain duplicates, it isn’t a bad idea to throw a duplicate checker into your workflow. Sometimes people do not understand that the data they have assembled has been entered by humans and humans make a lot of mistakes.
Eliminating duplicate records will improve the analytics that you are trying to determine. The unique tool is shown Figure 9. Notice that sometimes you have to deselect fields when determining what is duplicate or not, especially if you follow rule #1 above (deselect the Record ID).

Figure 9 – The usage of the unique tool. Notice that I deselected some fields in the configuration window.
4 – Use the Auto Field
One of my favorite tools is the auto field. This tool profiles the data to determine the data types for each field in your file. The auto field allows near optimal settings to be established for your data, such as string lengths and the integer and floating point data types needed to store the information. Figure 10 shows how I install the auto data field in the beginning of a workflow.

Figure 10 – The use of the auto field allows Alteryx to characterize the data before you begin working with it. The Auto Field tool reads through all the records of an input and sets the field type to the smallest possible size relative to the data contained within each field.
I recently made a couple of videos for a friend of mine that is just beginning to work with Alteryx. Although I was making the videos in response to him, I decided to include them in this article because they discuss the use of the auto field in the a couple of examples of reading from an Excel file (video 1) and a CSV file (video 2).
At the time I made the videos, I was guessing a little about the problems he was experiencing so I just made a generic video but I do reference him a couple of time. I didn’t want to take the time to re-make the videos for this article.
5 – Use A Join Tool For Easy Record Removal
Figure 3 contains a picture of a workflow (part 3a) that demonstrates this technique. In this workflow, the top line of operations identifies expense records that are matches between the original ticket purchased and the refunded ticket. Once these record id’s are found, a transpose operation is used to create a vertical list of records to be removed. These records were easy to identify because I used the record ID tool (Step #1). In the lower part of the workflow, the join operation is used to eliminate the records.
The clever part of the trick is this: The inner join will match the records I want to remove with the records in the complete database. By using only the left join results, all the remaining data flows through the workflow and the records I wanted to eliminate are dropped since I’m not using the results of the inner join.
6 – Other Techinques
There are other techniques that I am developing that would be nice to document, but this article is now quite long. I’ll save the other techniques for the next installment of this series.
Final Thoughts
I’m going to find a way to visit the Alteryx Irvine office and have a meeting in the bus. I’m also going to find a way to get one of those bus tee-shirts shown in the video.
I think the bus project was awesome to see and for a final insight into what the bus means to Alteryx, watch this bus installation video and see these great pictures!




It’s good to see that you use the same tools and approach that I tend to use…I’ve never really coded, but I like to modularize the workflow via containers as well, especially complex ones. It also makes it easier to re-use portions since you can just copy/paste a container vs having to lasso all of the relevant tools.
And I tool would love to have a meeting (and a beer) inside the Alteryx bus. 🙂
Pingback: How To Achieve Better Data Comprehension, Part 2 | 3danim8's Blog
Pingback: 3danim8's Blog - Using #Alteryx and #Tableau to Visualize and Understand Population Density